


Unexpected Outage
It's Friday night: I had just finished putting the kids to bed. As my wife and I were exhausted from the week, we were happy to have a quiet night.
The day before: My team and I pushed a small upgrade to one of our services infrastructure. We had previously tested this in our pre-production environment, so we had confidence in the stability of the system.
Suddenly, errors began flooding in fast: Multiple customers were reporting seemingly unrelated issues in the system. Our support engineers scrambled to find the cause.
Fortunately, we had a rollback plan in place.
With a few clicks, the previous service image was deployed, restoring order—for now.
Why Rollback Plans Matter
Beyond Mistakes: Having rollback plans is essentially doing proactive risk management. It's being aware that failure will happen eventually.
Your plan is your safety net: Having a rollback plan is like wearing a seatbelt in a car. You hope you never need it, but you're grateful it's there if you do.
Confidence and Reputation: The more robust your team's rollback plans are, the more confident they will be in making upgrades, which in turn fosters innovation and experimentation. An additional benefit is the rise of your customer trust.

Rollback Strategies
I have experience using a separate repository labeled “deployment” with a configuration file (xml) holding the image hash to be used - when a rollback is needed. This approach simplifies rollback processes, reduces the risk of deploying faulty images, and provides a clear history of deployed versions.
If you have ArgoCD - you can simply use the UI: navigate to the application details page, click the "History and Rollback" tab, select the desired healthy deployment from the history list, and click the "Rollback" button.
If you are a fan of CLI, use the command argocd app rollback <APP_NAME> <TARGET_REVISION>, where TARGET_REVISION is the desired healthy deployment revision.
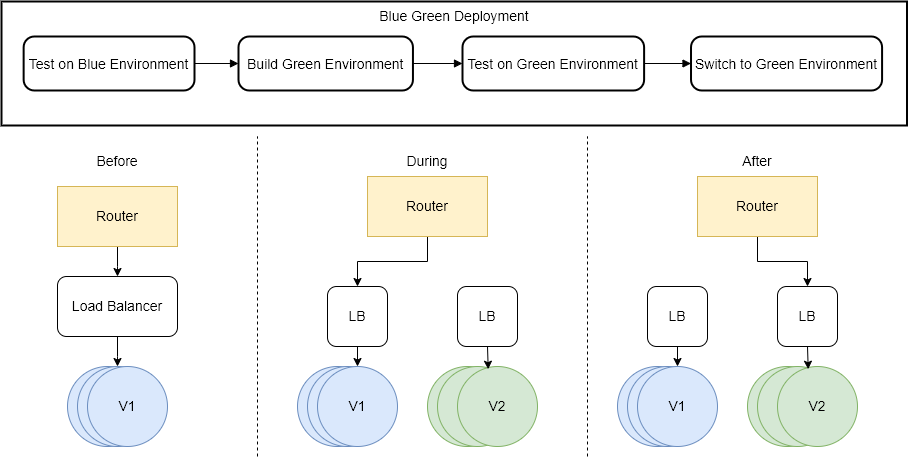
Blue/Green Deployments:
In blue-green deployment you essentially create two identical environments (blue and green) using these services, with the blue environment initially serving live traffic. Deploy the new application version to the green environment and perform testing. Once validated, you can shift traffic from blue to green using a load balancer or by swapping CNAME records. Services like Route 53 and Elastic Load Balancing help manage this traffic redirection. If issues arise, you can quickly revert traffic back to the blue environment.
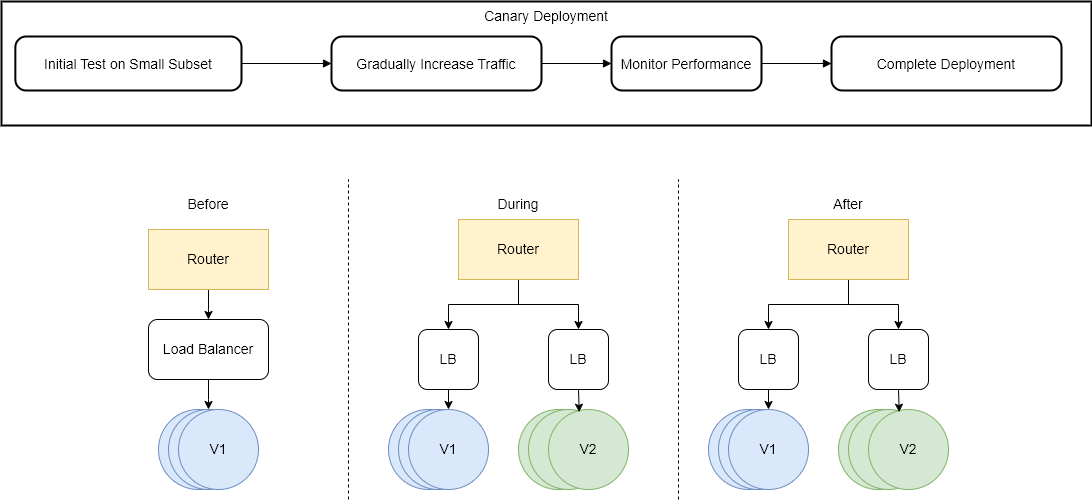
Canary Deployments:
First, let’s explain where the term “canary” comes from.
Miners used to send canaries to see if the bird would survive the level of oxygen in the deep underground mine, before sending down humans. A terrible analogy, I know… but this is what the industry uses. Leave a comment if you have a better idea for a metaphor we should adopt.
Canary deployments are like dipping your toes in the water before jumping into a pool. You test the waters gradually to make sure it's safe.
In a canary deployment you gradually move traffic from the existing (blue) environment to the new (green) one. In AWS for example, this can be done either by utilizing the feature of elastic load balancers (ELB) weights, or similarly the Route 53 weights on the DNS record level.
Additional Rollback Strategies
Database Schema Changes: Depending on your use case, you may find it useful to work with backwards-compatible changes, versioning schemas, and scripting migrations. There are tools such as Liquibase, Flyway, and Redgate that allow structured DB changes. Such tools come in handy when a gradual upgrade is done (see my next point about feature flags). In addition, it is extremely important that you test rollbacks for database scenarios, when possible.
Feature Toggles/Flags: Think how you could benefit from implementing a change that is disabled by default. Then, gradually enabling the change in a controlled manner, allowing for controlled rollbacks of database migrations, without redeployment. Tools such as LaunchDarkly or Tggl.io allow just that.
Learning from Mistakes
Incident #1
A few months ago, my team and I were doing a major upgrade on our MySQL database. The upgrade was scheduled to take place early Sunday morning, to avoid customer impact. The upgrade process was tested and verified in the pre-prod (staging) environment, so we considered the operation low risk.
My colleague reminded the team about the upcoming upgrade and the expected downtime. He assured that customers wouldn't be affected as it was scheduled outside of working hours.
I happened to be the on-call engineer during the upgrade, and of course I woke up to a pager duty alert early in the morning.
Apparently we had bots using our site. These are legitimate bots, scheduled to run during off peak hours - but apparently someone had forgotten to tell us about them.
Another unexpected factor was that the database upgrade took much longer in production than in the staging environment.
Where did we get lucky?
Because the bots could retry failed requests, there was no customer impact.
What could we have done better?
Snoozing the pager duty alarm could mitigate the noise, but this is potentially dangerous as it might mask other issues.
We could announce the scheduled maintenance ahead of time, put it in our team’s calendar, slack etc, and notify our clients.

Incident #2
In one of the companies I worked for, we employed Tag-based Releases. This allowed for flexibility. Instead of constantly building from a main branch with incremental builds, developers would create branches for specific features or releases. When a release was ready, it would be tagged with a specific version (often using semantic versioning) and deployed from that tag.
One day I was releasing a small feature to one of our services. I “bumped” the minor version, ran all the automation tests, and tagged my branch - let's call it 3.2.1.
I opened the Jenkins UI and in the dropdown typed 3.1.2.
Yes, I accidentally deployed an old version of one of our services.
As you would expect, this incident resulted in some customer impact.
How could this be avoided?
Sometimes we have a test plan, often just some smoke tests, to check that everything is running smoothly. This obviously is not always enough.
One idea was to prevent deploying old tags from the UI, or to add a confirmation like, 'You are about to deploy an old version. Click yes to proceed.' This would help prevent human errors, but the best way is to think like a QA. Have an API call or input that works, and one that does not work - prior to the new feature being deployed. Then test them to verify your changes are in.
This might seem like overhead, but as I mentioned earlier, confidence is crucial.
Lesson learned: always have a backup plan, or in other words - a way for you to rollback.
Having a solid rollback plan is like a security blanket for your team, allowing them to take risks and innovate without fear of failure.
Building Your Rollback Plan
There's No Universal Rollback Strategy: The best strategy depends on application architecture, complexity, and risk tolerance.
Key Considerations: Ask yourself or your team the following questions to determine the right approach:
What would be an acceptable downtime?
How would you monitor rollback success?
What is your rollback plan to revert the data changes?
Deployment and Rollback Tools:
Deployment Automation: Tools like Jenkins, GitLab CI, Azure DevOps, AWS CodeDeploy, Octopus Deploy, and Argo CD automate deployments and often have built-in rollback capabilities to revert to previous versions.
Container Orchestration: Kubernetes and similar container orchestration tools have built in features like rolling updates with automatic rollback on failure.
Customized products. Netflix uses its self-built Spinnaker for canary rollout deployment.
Conclusion
Circling back to my experience with the database upgrade: When you have a rollback plan that is solid, you have confidence to make changes. Don’t move fast and break things. Think fast and make things.
Call to Action: I encourage you to assess your rollback readiness, or even start small with simple rollback procedures for critical components.
Take Time and select the right tools
What about you? which rollback strategies or tools does your team use? Let me know in the comments.
I hope this was fun to read at least as much as this was fun to write! if so, please considering sharing on social, or clicking the like/heart button below. Thank you for reading!
Abstract images generated with leonardo.ai